If you have at least let’s say 2-3 years of experience in programming, then there is a big chance, that you faced at least once a problem when two threads were trying to access some resource at the same time. At that time you ended with race condition or undefined behavior. What was the solution of the problem then? Your choice as a beginner? Probably an old, plain mutex object.
Many developers that studied information technology would say „hey, this is simple, dont’ waste your time writing about that stuff, everybody knows that”.
But is it for real? I feel that many people are not geeting deep enough and thus they don’t have enough understanding of what’s really happening under the hood.
Mutual exclusion
Imagine a situation where you created a program that has 2 threads. Each thread is working on the same data structure. Take a look at the picture:
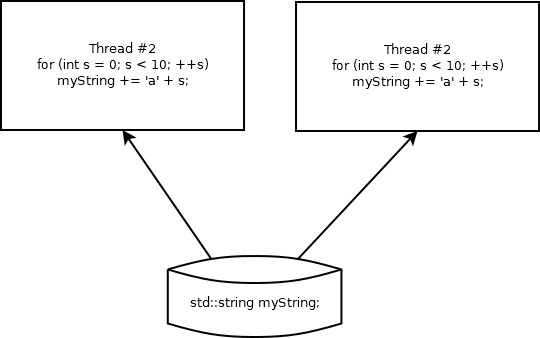
Let’s break these two threads into possible implementation of std::string::operator+= in assembly code:
| Thread #1 | Line | Thread #2 |
| mov edx, current_size | 0 | mov edx, current_size |
| cmp current_size, allocated_size | 1 | cmp current_size, allocated_size |
| jae reallocate_buffer | 2 | jae reallocate_buffer |
| ; here code of actual push_back | 3 | ; here code of actual push_back |
| … | 4 | … |
| reallocate_buffer: | 5 | reallocate_buffer: |
| mov eax, 2 | 6 | mov eax, 2 |
| mov ecx, allocated_size | 7 | mov ecx, allocated_size |
| mul ecx | 8 | mul ecx |
(This implementation is just an example to demonstrate the problem, the real implementation of std::string is different).
Let’s imagine now that an operating system has switched context from thread#1 to another thread at line #5 while the second thread would be executing line #0.
Both threads are working on the same data structure. While thread#1 is frozen, thread#2 is actively executing the code. Thread #2 will put an actual data into buffer and kernel will switch to thread #1 and continue execution on line #5. At this moment we have no information whether thread#2 already completed it’s operation on the buffer or the copy operation is in the middle and only a small part of string has been appended. The thread#1 is doing the reallocation and a big chance that an address of the memory block would change. After some quant of time kernel would switch to thread#2 and resume memcpy operation on a buffer that is already freed. Segmentation fault, crash!
Critical region
None of this situation would not happen if an access to the resource would be synchronized. This is the moment where mutex is the thing that you need.
Critical region is a block of code where modification and/or read operation is being performed and is being synchronized using exclusive lock on mutex. It’s best to keep this region as small as possible, and make them deterministic in terms of execution in time, because other threads might want to have an access while your program is stuck in a critical region where MessageBox is waiting to be closed (I have seen such things in my life…).
Possible implementation
A possible implementation would be an instruction of x86 cpu that would be atomic and is able to exchange register with memory value in a single, atomic step. A good choice here would be XCHG instruction. A number of different (sometimes better, but more complicated) solutions are used. For the sake of the very simple example I decided to use XCHG.
This is how could mutex be implemented using XCHG instruction:
mov edx, 1 ; load constant into reg
mov ecx, [mx] ; load address of mx into reg
xchg [ecx], edx ; atomically exchange values of
; dereferenced variable and the
; registry containing 1
cmp [ecx], edx ; check if value has changed
jne finish ; finish proc if mx is changed to 1
; (mutex locked)
call SwitchToThread ; yield to another thread
; and give another try after jmp
jmp try_lockThe crucial step is xchg [ecx], edx where the real exchange occurs. Then we check if the value has changed. Given that we tried to change it to value of 1, if it hasn’t been changed, then it means that the lock was unsuccesfull and we may inform the thread scheduler to switch to another thread and give a try another time.
Switching to another thread improves the general performance because we don’t spin in place inside tight loop, but we give a chance for other threads to do their work.
Most of the libraries like boost::threads or threads from C++11 are not implementing user space mutexes. The presented code of mutex implementation is usually located inside kernel space of your operating system and exposed by public API.
Tags: C++ multithreading mutex x86 asm